
This is the second of two posts based on a testing tutorial I'm writing with David Duvenaud.
In my last post, I talked about checking the MCMC updates using unit tests. Most of the mistakes I've caught in my own code were ones I caught with unit tests. (Naturally, I have no idea about the ones I haven’t caught.) But no matter how thoroughly we unit test, there are still subtle bugs that slip through the cracks. Integration testing is a more global approach, and tests the overall behavior of the software, which depends on the interaction of multiple components.
When testing samplers, we’re interested in testing two things: whether our algorithm is mathematically correct, and whether it is converging to a correct solution. These two goals are somewhat independent of each other: a mathematically correct algorithm can get stuck and fail to find a good solution, and (counterintuitively) a mathematically incorrect algorithm can often find the correct solution or at least get close. This post is about checking mathematical correctness.
The gold standard for testing MCMC algorithms is the Geweke test, as described in Geweke’s paper “Getting it right: joint distribution tests of posterior simulators.” [1] The basic idea is simple: suppose you have a generative model over parameters $\theta$ and data $x$, and you want to test an MCMC sampler for the posterior $p(\theta | x)$. There are two different ways to sample from the joint distribution over $\theta$ and $x$. First, you can forward sample, i.e. sample $\theta$ from $p(\theta)$, and then sample $x$ from $p(x | \theta)$. Second, you can start from a forward sample, and run a Markov chain where you alternate between
- Updating $\theta$ using one of your MCMC transition operators, which should preserve the distribution $p(\theta | x) $, and
- resampling the data from the distribution $p(x | \theta) $.
Since each of these operations preserves the stationary distribution, each step of this chain is a perfect sample from the joint distribution $p(\theta, x)$.
If your sampler is correct, then each of these two procedures should yield samples from exactly the same distribution. You can test this by comparing a variety of statistics of the samples, e.g. the mean of $x$, the maximum absolute value of $\theta$, and so on. No matter what statistics you choose, they should be indistinguishable between the two distributions.
The beauty of this approach is that it amplifies subtle bugs in the sampler. For instance, suppose we have a bug in our sampler which makes the posterior noise variance 1% too large. This would be nearly impossible to detect by simply running your model on real data and seeing if the results look plausible. Now consider what the Geweke test would do. After the parameters are sampled, the data will be generated with a 1% larger noise variance. When the parameters are resampled, the noise variance will be 1% too large on top of that, or 2%. Pretty soon, the noise variance will explode.
In his paper, Geweke uses frequentist hypothesis tests to compare the distributions. This can be difficult, however, since you’d need to account for dependencies between the samples in order to determine significance. A simpler approach is to make a P-P plot of the statistics. If it’s very close to a straight line, the test "passes":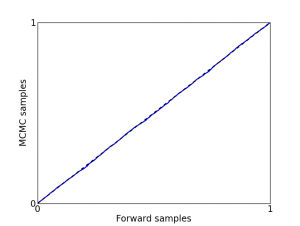
If it’s far off, you have a bug: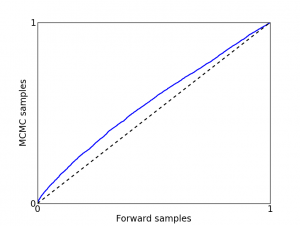
If the results are noisy and unclear, generate more forward samples and run the chains for longer:![]()
(While these figures are synthetic, they're representative of outputs I've gotten in the past.) If you wind up with the third case, and you can't run the sampler any longer because it's already too slow, try reducing the number of data points. Not only does this speed up each iteration, but it also makes the chains mix faster -- the more data points there are, the stronger the coupling between $\theta$ and $x$.
There’s a major drawback of the Geweke test, unfortunately: it gives you no indication of where the bug might be. All you can do is keep staring at your code till you find the bug. Therefore, there’s no point in running this test until all your unit tests already pass. This meshes with the general test-driven development methodology, where you get your unit tests to pass before the integration tests.
[1] J. Geweke. Getting it right: joint distribution tests of posterior simulators. JASA, 2004.